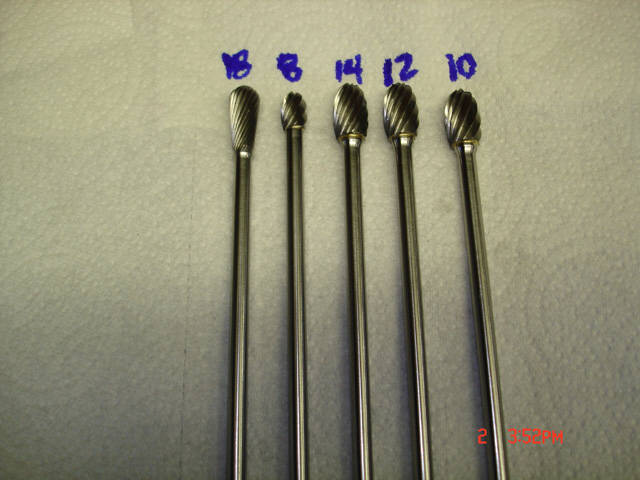
A Collection of Carbide Porting Burrs
Bill Jones' Photo Gallery Page 15
Here are some examples of 6" long carbides that I prefer for my head porting
---------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------
-These were recently special ordered and purchased from Tom Carrella @ Circofile as part of a $1135, 56 piece order so that I could get the price down to something fairly reasonable
.
-The tooth counts on these are not commonly available without some sort of a special order.
-
this $1135 purchase buys these at 50% off of one piece sales.
-Altho I didn't buy'm to sell'm I will consider selling to CASH paying persons if you can't find similar burrs elsewhere.
---------------------------------------------------------------------------------------------------
1-far left is SN3.5CR-18---really good for working around corners and for the crest of the port floors.
-this is 7/16" diameter.
-I have 6, paid $19.38 each---will sell for $25 each.
-the only other place I have seen this style of burr is from Mondello where his 6" shank number is an RT4-5 (RT4-6-18RC) and costs $38.
-I bought 4 of these from Mondello and I was really impressed with how well they work for the short turn radius's of the floors---just like a
magic tool.
-One problem I did have tho was one of the brand new burrs popped the burr right off the shank the first time I used it
-So I feel that this particular type of burr should not be used very aggressively or much pressure---and this is because there is only 1/4" of
brazed connection to the burr--where most other burrs have larger braze pads on the shank ends.
-------------------------------------------------------------------------------------------------
2-second from left is an SE3-8 with 8 flutes--this is pretty aggressive but has two more flutes that common non-ferrous burrs.
-this is a 3/8" diameter.
-I have 4 of these,
paid $14.45 each---will sell for $20 each
-I don't know of anybody who sells this tooth count--you either get a standard 6 flute none ferrous burr or you can get 18 flutes from
Mondello's catalog for $24.
--------------------------------------------------------------------------------------------------
3-the next 3 are all SE5's with 14, 12, and 10 flutes.
-these are 1/2" diameter
-I have 6 of each tooth count---paid $19.38 each ---will sell for $25 each.
-here again looking at Mondellos catalog the coarsest you can get in 6" shank is 20 flutes and they are $30.
---------------------------------------------------------------------------------------------------
4-not shown but I also bought a group of 6 each SE4's with 12,10 and 8 flutes
-these are 7/16" diameter.
-I paid $19.17 each for these and I'd also sell any of'm for $25 each.
-same deal here--Mondellos catalog only shows a 20 flute in 6" and they are also $30.
---------------------------------------------------------------------------------------------------
To sell these to anybody other than local people----where I have to mail'm---I will mail one or a handful within the 48 USA states for $5 per package.
If a person wanted to buy and was from out of the 48 USA states---I'd have to look at mailing costs but quite likely $15 would ship a handful to about anywhere.
---------------------------------------------------------------------------------------------------
When looking at these up close----the flutes as ground by Circofile/Thompson tool Supply don't have a nice smooth relief on the flutes and they are pretty crude compared to other burrs that I have previously boughten elsewhere---places like Mondello, BLP, etc.---so I don't know how well they will last particularly on cast iron or when cutting seat metal rings.
-I am actually somewhat disappointed in this fact but I haven't used any of'm yet to really see how well they cut.